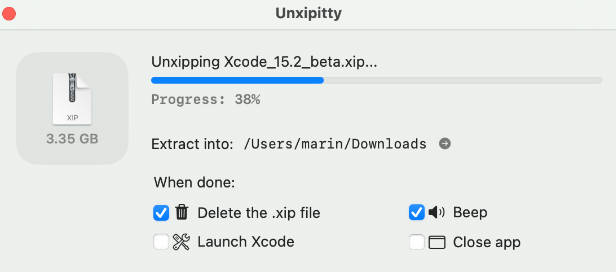
unxip
unxip is a command line-tool designed for rapidly unarchiving Xcode XIP files and writing them to disk with good compression. It’s purpose-built to outperform Bom (which powers xip(1) and Archive Utility) in both performance and on-disk usage.
Installation
Not much installation is needed to use unxip: simply download unxip.swift and compile it using swiftc -parse-as-library -O unxip.swift to produce the unxip binary.
Usage
The intended usage of unxip is with a single command line parameter that represents the path to an XIP from Apple containing Xcode. For example:
$ unxip Xcode_13.3_beta.xip # will produce Xcode-beta.app in the current directory
The tool is still somewhat rough and its error handling is not very good at the moment, so when things go wrong it will often crash preemptively when possible or behave strangely when not. For best results, ensure that the directory you are running it from does not contain any existing Xcode(-beta).app bundles and that you are running it on a modern version of macOS on a fast APFS filesystem. For simplicity, unxip does not perform any signature verification, so if authentication is important you should use another mechanism (such as a checksum) for validation.
Design
As a purpose-built tool, unxip outperforms Bom because of several key implementation decisions. Heavy use of Swift Concurrency allows unxip to unlock parallelization opportunities that Bom largely misses, and the use of LZFSE rather than the simpler LZVN gives it higher compression ratios. To understand its design, it’s important to first be familiar with the Xcode XIP format and APFS transparent compression.
XIPs, including the ones that Xcode come in, are XAR archives with nested, individually-compressed content. However, unlike most XARs the one Xcode ships in only has two files: a bzip2-compressed Metadata that is just a few hundred bytes large, and a multi-gigabyte “uncompressed” Content that contains the data we care about. This file itself is an apparently proprietary archive format called pbzx. However, the format is fairly straightforward and several people on the internet have tried to reverse engineer it. This tool contains an independent implementation that nonetheless shares the core details. Specifically, the compressed content is an ASCII-representation CPIO archive, which has been split apart into 16MB chunks that have either been compressed with LZMA or included as-is.
Parsing this CPIO archive gives the necessary information need to reconstruct an Xcode bundle, but unxip (and Bom) go through an additional step to apply transparent APFS compression to files that could benefit from it, significantly reducing size on-disk. unxip chooses to use the LZFSE algorithm due to its performance and compression characteristics.
On the whole, this procedure is designed to be fairly linear, with the XIP being read sequentially, producing LZMA chunks that are decoded in order to create the CPIO archive, which can then be streamed to reconstruct an Xcode bundle. Unfortunately, a naive implementation of this is process cannot perform well due to the varying performance bottlenecks of each step. In addition the size of Xcode makes it infeasible to operate it entirely in memory. Instead, unxip parallelizes intermediate steps and then streams results in linear order, allowing for much better processor utilization and without having to handle the entire file at once.
On modern processors, LZMA decoding can proceed at ~100 MB/s, which not fast enough to reach the speeds needed for unxip. To decompress the pbzx archive, unxip instead carves out each chunk into its own task (which is fairly straightforward from the metadata included in the file format) and decompresses each in parallel. To limit memory usage, a cap is applied to how many chunks are resident in memory at once. Since the next step (parsing the CPIO)requires logical linearity, completing chunks are temporarily stored until their preceding ones complete, then they are all yielded together. This preserves order while still allowing multiple chunks to be decoded in parallel, allowing for effective decoding speeds approaching 1 GB/s.
The linear chunk stream (now a CPIO) is then parsed linearly to extract files, directories, and their associated metadata. CPIOs are naturally ordered–for example, all additional hardlinks must come after the original file–but Xcode’s has an additional nice property that it’s been sorted so that all directories appear before the files inside of them. This allows for a sequential stream of filesystem operations to correctly produce the bundle, without running into errors with missing intermediate directories or link targets.
While simplifying the implementation, this order makes it difficult for unxip to efficiently schedule filesystem operations and transparent compression, which (because of the performance of LZMA decompression and file parsing) is the bottleneck for writing to disk. To resolve this, a dependency graph is created for each file (directories, files, and symlinks depend on their parent directory’s existence, hardlinks require their target to exist) and then the task is scheduled in parallel with those constraints. New file writes are particularly expensive because compression is applied before the data is written to disk. While this step is already parallelized to some extent because of the graph described earlier, Apple’s decmpfs implementation also allows for additional parallelism because it chunks data internally at 64KB chunk boundaries, which we can run in parallel.
Overall, this architecture allows unxip to utilize CPU cores and dispatch disk writes fairly well. It is likely that there is still some room for improvement in its implementation, especially around the constants chosen for batch sizes and backoff intervals (some of which can probably be done much better by the runtime itself once it is ready). Ideas on how its performance can be further improved are always welcome ?