A Mobile Text-to-Image Search Powered by AI
A minimal demo demonstrating semantic multimodal text-to-image search using pretrained vision-language models.
Features
- text-to-image retrieval using semantic similarity search.
- support different vector indexing strategies(linear scan and KMeans are now implemented).
Screenshot
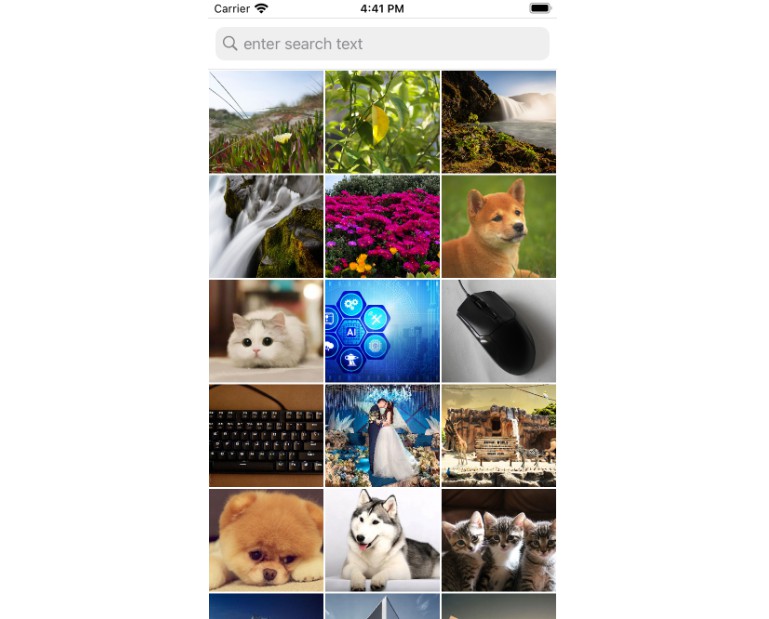
- All images in the gallery

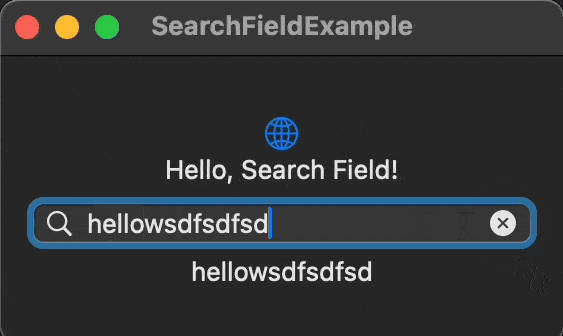
- Search with query Three cats

Install
- Download the two TorchScript model files(text encoder, image encoder) into models folder and add them into the Xcode project.
- Required dependencies are defined in the Podfile. We use Cocapods to manage these dependencies. Simply do 'pod install' and then open the generated .xcworkspace project file in XCode.
pod install
- This demo by default load all images in the local photo gallery on your realphone or simulator. One can change it to a specified album by setting the albumName variable in getPhotos method and replacing assetResults in line 117 of GalleryInteractor.swift with photoAssets.
Todo
- Basic features
- [x] Accessing to specified album or the whole photos
- [x] Asynchronous model loading and vectors computation
- Indexing strategies
- [x] Linear indexing(persisted to file via built-in Data type)
- [x] KMeans indexing(persisted to file via NSMutableDictionary)
- [ ] Ball-Tree indexing
- [ ] Locality sensitive hashing indexing
- Choices of semantic representation models
- [x] OpenAI's CLIP model
- [ ] Integration of other multimodal retrieval models
- Effiency
- [ ] Reducing memory consumption of models(ViT/B-32 version of CLIP takes about 605MB for storage and 1GB for runtime on iPhone)