GPTEncoder

Swift BPE Encoder/Decoder for OpenAI GPT Models. A programmatic interface for tokenizing text for OpenAI GPT API.
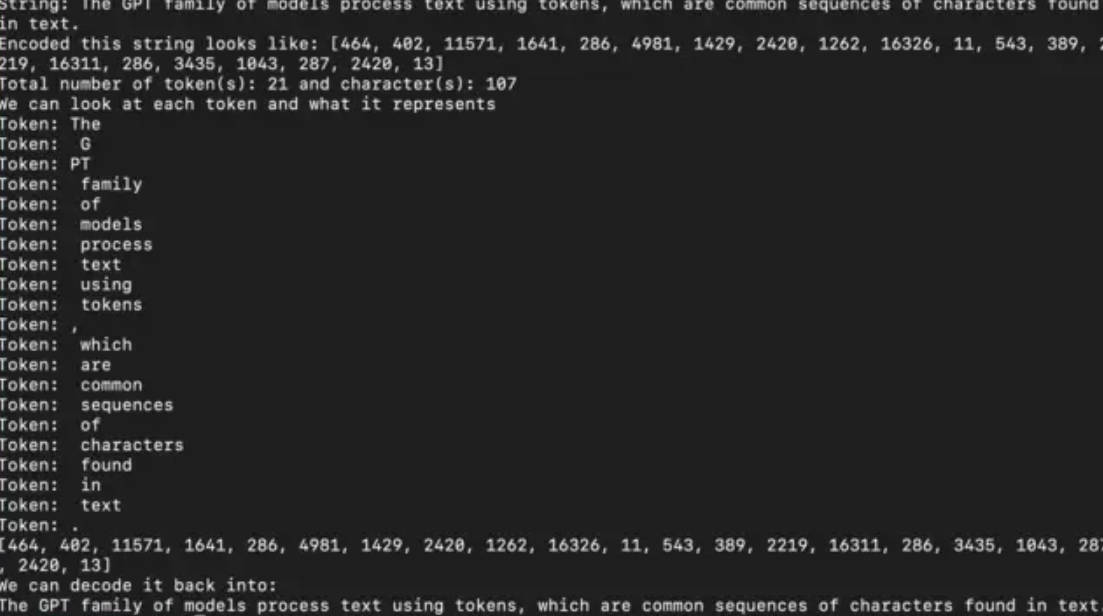
The GPT family of models process text using tokens, which are common sequences of characters found in text. The models understand the statistical relationships between these tokens, and excel at producing the next token in a sequence of tokens.
You can use the tool below to understand how a piece of text would be tokenized by the API, and the total count of tokens in that piece of text.
This library is based on nodeJS gpt-3-encoder and OpenAI Official Python GPT Encoder/Decoder
Supported Platforms
- iOS/macOS/watchOS/tvOS
- Linux
Installation
Swift Package Manager
- File > Swift Packages > Add Package Dependency
- Add – Add https://github.com/alfianlosari/GPTEncoder.git
Cocoapods
platform :ios, '15.0'
use_frameworks!
target 'MyApp' do
pod 'GPTEncoder', '~> 1.0.0'
end
Usage
let encoder = SwiftGPTEncoder()
let str = "The GPT family of models process text using tokens, which are common sequences of characters found in text."
let encoded = encoder.encode(text: str)
print("String: \(str)")
print("Encoded this string looks like: \(encoded)")
print("Total number of token(s): \(encoded.count) and character(s): \(str.count)")
print("We can look at each token and what it represents")
encoded.forEach { print("Token: \(encoder.decode(tokens: [$0]))") }
print(encoded)
let decoded = encoder.decode(tokens: encoded)
print("We can decode it back into:\n\(decoded)")
Encode
To encode a String to array of Int tokens, you can simply invoke encode passing the string.
let encoded = encoder.encode(text: "The GPT family of models process text using tokens, which are common sequences of characters found in text.")
// Output: [464, 402, 11571, 1641, 286, 4981, 1429, 2420, 1262, 16326, 11, 543, 389, 2219, 16311, 286, 3435, 1043, 287, 2420, 13]
Decode
To decode an array of Int tokens back to the String you can invoke decode passing the tokens array.
let decoded = encoder.decode(tokens: [464, 402, 11571, 1641, 286, 4981, 1429, 2420, 1262, 16326, 11, 543, 389, 2219, 16311, 286, 3435, 1043, 287, 2420, 13])
// Output: "The GPT family of models process text using tokens, which are common sequences of characters found in text."
Clear Cache
Internally, a cache is used to improve performance when encoding the tokens, you can reset the cache as well.
encoder.clearCache()