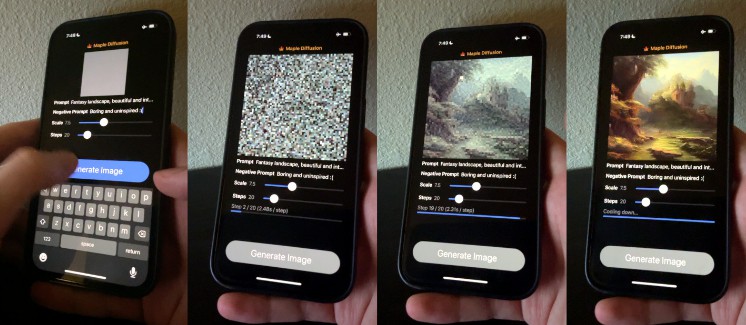
Native Diffusion Swift Package
Native Diffusion runs Stable Diffusion models locally on macOS / iOS devices, in Swift, using the MPSGraph framework (not Python).
This is the Swift Package Manager wrapper of Maple Diffusion. It adds image-to-image, Swift Package Manager package, and convenient ways to use the code, like Combine publishers and async/await versions. It also supports downloading weights from any local or remote URL, including the app bundle itself.
Would not be possible without
- @madebyollin who wrote the Metal Performance Shader Graph pipeline
- @GuiyeC who wrote the image-to-image implementation
Features
Get started in 10 minutes
- Extremely simple API. Generate an image in one line of code.
Make it do what you want
- Flexible API. Pass in prompt, guidance scale, steps, seed, and an image.
- One-off conversion script from .ckpt to Native Diffusion’s own memory-optimized format
- Supports Dreambooth models.
Built to be fun to code with
- Supports async/await, Combine publisher and classic callbacks.
- Optimized for SwiftUI, but can be used in any kind of project, including command line, UIKit, or AppKit
Built for end-user speed and great user experience
- 100% native. No Python, no environments, your user don’t need to install anything first.
- Model download built in. Point it to a web address with the model files in a zip archive. The package will download and install the model for later use.
- As fast or faster than a server in the cloud on newer Macs
Commercial use allowed
- MIT Licensed (code). We’d love attribution, but it’s not needed legally.
- Generated images are licensed under the CreativeML Open RAIL-M license, meaning you can use the images for virtually anything, including commercial use.
Usage
One-line diffusion
In its simplest form it’s as simple as one line:
let image = try? await Diffusion.generate(localOrRemote: modelUrl, prompt: "cat astronaut")
You can give it a local or remote URL or both. If remote, the downloaded weights are saved for later.
The single line version is currently limited in terms of parameters.
See examples/SingleLineDiffusion for a working example.
As an observable object
Let’s add some UI. Here’s an entire working image generator app in a single SwiftUI view:

struct ContentView: View {
// 1
@StateObject var sd = Diffusion()
@State var prompt = ""
@State var image : CGImage?
@State var imagePublisher = Diffusion.placeholderPublisher
@State var progress : Double = 0
var anyProgress : Double { sd.loadingProgress < 1 ? sd.loadingProgress : progress }
var body: some View {
VStack {
DiffusionImage(image: $image, progress: $progress)
Spacer()
TextField("Prompt", text: $prompt)
// 3
.onSubmit { self.imagePublisher = sd.generate(prompt: prompt) }
.disabled(!sd.isModelReady)
ProgressView(value: anyProgress)
.opacity(anyProgress == 1 || anyProgress == 0 ? 0 : 1)
}
.task {
// 2
let path = URL(string: "http://localhost:8080/Diffusion.zip")!
try! await sd.prepModels(remoteURL: path)
}
// 4
.onReceive(imagePublisher) { r in
self.image = r.image
self.progress = r.progress
}
.frame(minWidth: 200, minHeight: 200)
}
}
Here’s what it does
- Instantiate a
Diffusionobject - Prepare the models, download if needed
- Submit a prompt for generation
- Receive updates during generation
See examples/SimpleDiffusion for a working example.
DiffusionImage
An optional SwiftUI view that is specialized for diffusion:
- Receives drag and drop of an image from e.g. Finder and sends it back to you via a binding (macOS)
- Automatically resizes the image to 512×512 (macOS)
- Lets users drag the image to Finder or other apps (macOS)
- Blurs the internmediate image while generating (macOS and iOS)
Install
Add https://github.com/mortenjust/native-diffusion in the “Swift Package Manager” tab in Xcode
Preparing the weights
Native Diffusion splits the weights into a binary format that is different from the typical CKPT format. It uses many small files which it then (optionally) swaps in and out of memory, enabling it to run on both macOS and iOS. You can use the converter script in the package to convert your own CKPT file.
Option 1: Pre-converted Standard Stable Diffusion v1.5
By downloading this zip file, you accept the creative license from StabilityAI.
Download ZIP. Please don’t use this URL in your software.
We’ll get back to what to do with it in a second.
Option 2: Preparing your own ckpt file
If you want to use your own CKPT file (like a Dreambooth fine-tuning), you can convert it into Maple Diffusion format
-
Download a Stable Diffusion model checkpoint to a folder, e.g. ~/Downloads/sd (sd-v1-5.ckpt, or some derivation thereof)
-
Setup & install Python with PyTorch, if you haven’t already.
# Grab the converter script
cd ~/Downloads/sd
curl https://raw.githubusercontent.com/mortenjust/maple-diffusion/main/Converter%20Script/maple-convert.py > maple-convert.py
# may need to install conda first https://github.com/conda-forge/miniforge#homebrew
conda deactivate
conda remove -n native-diffusion --all
conda create -n native-diffusion python=3.10
conda activate native-diffusion
pip install torch typing_extensions numpy Pillow requests pytorch_lightning
./native-convert.py ~/Downloads/sd-v1-4.ckpt
The script will create a new folder called bins. We’ll get back to what to do with it in a second.
-
Download a Stable Diffusion model checkpoint to a folder, e.g.
~/Downloads/sd(sd-v1-5.ckpt, or some derivation thereof) -
Setup & install Python with PyTorch, if you haven’t already.
# Grab the converter script
cd ~/Downloads/sd
curl https://raw.githubusercontent.com/mortenjust/maple-diffusion/main/Converter%20Script/maple-convert.py > maple-convert.py
# may need to install conda first https://github.com/conda-forge/miniforge#homebrew
conda deactivate
conda remove -n native-diffusion --all
conda create -n native-diffusion python=3.10
conda activate native-diffusion
pip install torch typing_extensions numpy Pillow requests pytorch_lightning
./native-convert.py ~/Downloads/sd-v1-4.ckpt
The script will create a new folder called bins. We’ll get back to what to do with it in a second.
FAQ
Can I use a Dreambooth model?
Yes. Just copy the alpha* files from the standard conversion. This repo will include these files in the future. See this issue.
Does it support image to image prompting?
Yes. Simply pass in an initImage to your SampleInput when generating.
It crashes
You may need to regenerate the model files with the python script in the repo. This happens if you converted your ckpt model file before we added image2image.
Can I contribute? What’s next?
Yes! A rough roadmap:
- Stable Diffusion 2.0: – new larger output images, upscaling, depth-to-image
- Add in-painting and out-painting
- Generate other sizes and aspects than 512×512
- Upscaling
- Dreambooth training on-device
- Tighten up code quality overall. Most is proof of concept.
- Add image-to-image
See Issues for smaller contributions.
If you’re making changes to the MPSGraph part of the codebase, consider making your contributions to the single-file repo and then integrate the changes in the wrapped file in this repo.
How fast is it?
On my MacBook Pro M1 Max, I get ~0.3s/step, which is significantly faster than any Python/PyTorch/Tensorflow installation I’ve tried.
On an iPhone it should take a minute or two.
To attain usable performance without tripping over iOS’s 4GB memory limit, Native Diffusion relies internally on FP16 (NHWC) tensors, operator fusion from MPSGraph, and a truly pitiable degree of swapping models to device storage.
Does it support Stable Diffusion 2.0?
Not yet. Would love some help on this. See above.
I have a question, comment or suggestion
Feel free to post an issue!