QuietNow
Apple Music Sing leverages the-built in sound isolation Audio Unit. This is a rudimentary application to configurably isolate vocals.
Usage
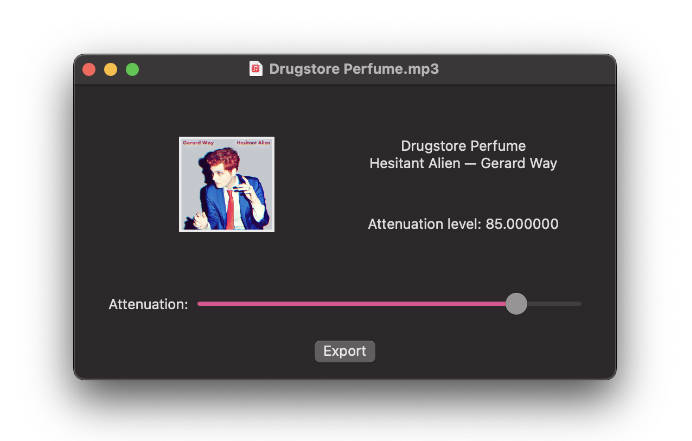
Build and run on macOS, iPadOS, or iOS. Open any audio file, and playback will begin immediately. Adjust the slider accordingly, and enjoy!
You may additionally export and save a M4A of your current song with the current vocal attenuation level applied.

(I did say it was rudimentary. Hopefully it will serve as an example how to leverage the audio unit ?
Vocal Isolation?
Beginning in iOS 16.0 and macOS 13.0, a new audio unit entitled AUSoundIsolation silently appeared. As of writing:
- If you search the unit’s name’s on GitHub, there are 9 results.
- If you search this on Google/Bing/[…], the majority of results are Audacity users complaining about it being incompatible.
(…in other words, another typical unannounced and undocumented addition. Thanks, Apple!)
This unit is silently the backbone of Apple Music Sing. A custom neural network is applied to the isolation audio unit, separating and reducing vocals. This is done entirely on-device, hence Apple’s mention of:
Apple Music Sing is available on iPhone 11 and later and iPhone SE (3rd generation) using iOS 16.2 or later.
This aligns with their second-generation neural engine (present in A13 and above).
Audio Unit Parameters
| Parameter ID | Name | Value | Description |
|---|---|---|---|
| 95782 | UseTuningMode | 1.0 | The default is 1.0, used as a boolean. |
| 95783 | TuningMode | 1.0. | Similarly, this is set to 1.0. |
| 0 | kAUSoundIsolationParam_WetDryMixPercent |
85.0 | The amount to remove vocals by. Should be 0.0 to 100.0 – any value above increases vocal volumes significantly. (Try 1000.0 with your volume set to 1%.) |
Audio Unit Properties
| Property ID | Name | Description |
|---|---|---|
| 7000 | CoreAudioReporterTimePeriod | ? |
| 30000 | NeuralNetPlistPathOverride | The path to load the property list named aufx-nnet-appl.plist for the neural network. |
| 40000 | NeuralNetModelNetPathBaseOverride | The directory to load weights and so forth from. If not specificed, the ModelNetPathBase within its property list is utilized. |
| 50000 | DeverbPresetPathOverride | ? |
| 60000 | DenoisePresetPath | ? |
(If you’re a lone soul frantically searching for what these are in the near future, pull requests with their description would be much appreciated.)
MediaPlaybackCore.framework (providing this functionality) appears to only set “NeuralNetModelNetPathBase” and “NeuralNetModelNetPathBaseOverride”, and by default sets “DereverbPresetPathOverride” to null (thus disabling it).
Despite how Apple Music applies it, lyrics (whether timed, or timed by word) are not a factor whatsoever in the model. This is especially apparent if you listen to any song where vocals are distorted, or background instrumentals drown out vocals. I imagine Apple simply does not provide the option for non-timed songs because karaoke wouldn’t be nearly as fun.