ConcurrencyBenchmark
Benchmarks for CPU-bound computation comparing different parallelization strategies.
Usage
Run the benchmarks:
swift run -c release benchmark run \
--cycles 3 \
--max-size 256k \
BenchmarkData/benchmark-data.json
Create a chart:
swift run -c release benchmark render \
BenchmarkData/benchmark-data.json \
BenchmarkData/chart.png \
--amortized false
For more options:
- See the Swift Collections Benchmark Getting Started Guide
swift run -c release benchmark run --helpswift run -c release benchmark render --help
Analysis
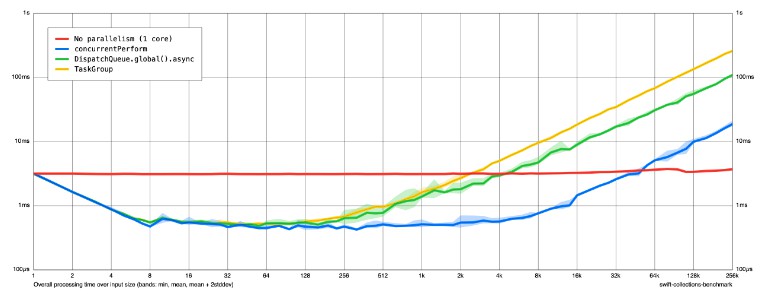
This chart was created on an Apple M1 Pro (10 cores):

Note: the x axis should be called “number of subtasks”, not “input size”:
- The benchmark always performs 10 million computations (this is the
totalWorkloadvariable in the code) - If “input size” = 10, the workload is split into 10 “subtasks”. E.g. we’re calling
concurrentPerformwith 10 iterations, where each iteration perform 10 million / 10 = 1 million computations. Same for theTaskGroup(10 child tasks) andDispatchQueue.global.async()(10 work items passed to the global queue) benchmarks. - For large input sizes, this creates a very large number of subtasks with each subtask doing very little work. This is why the curves go up as the number of subtasks increases.
- The “No parallelism (1 core)” task always performs the same number of computations, regardless of input size. This is why the line is flat.
- We’re passing
--amortized falsewhen rendering the chart to show the total elapsed time. Without this, the chart would depict the time per “subtask”, which is meaningless to us because the amount of work per subtask isn’t constant.
Observations:
- The pure computational work takes ~3 ms on this machine (see the flat line).
- At 1 subtask (no parallelism), all strategies have effectively the same performance (as expected).
- At the optimal level of parallelism (around 32–64 subtasks), all parallelization strategies are are almost 10× as fast as the single-core benchmark (as expected).
DispatchQueue.concurrentPerformis more efficient thanTaskGroupandDispatchQueue.global().asyncas the number of subtasks increases.