swift-transformers
This is a collection of utilities to help adopt language models in Swift apps. It tries to follow the Python transformers API and abstractions whenever possible, but it also aims to provide an idiomatic Swift interface and does not assume prior familiarity with transformers or tokenizers.
Rationale and Overview
Please, check our post.
Modules
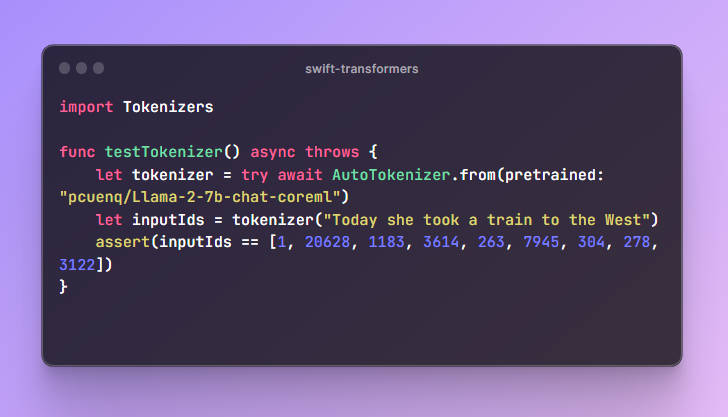
Tokenizers. Utilities to convert text to tokens and back. Follows the abstractions intokenizersandtransformers.js. Usage example:
import Tokenizers
func testTokenizer() async throws {
let tokenizer = try await AutoTokenizer.from(pretrained: "pcuenq/Llama-2-7b-chat-coreml")
let inputIds = tokenizer("Today she took a train to the West")
assert(inputIds == [1, 20628, 1183, 3614, 263, 7945, 304, 278, 3122])
}
However, you don’t usually need to tokenize the input text yourself – the Generation code will take care of it.
-
Hub. Utilities to download configuration files from the Hub, used to instantiate tokenizers and learn about language model characteristics. -
Generation. Algorithms for text generation. Currently supported ones are greedy search and top-k sampling. -
Models. Language model abstraction over a Core ML package.
Supported Models
This package has been tested with autoregressive language models such as:
- GPT, GPT-Neox, GPT-J.
- SantaCoder.
- StarCoder.
- Falcon.
- Llama 2.
Encoder-decoder models such as T5 and Flan are currently not supported. They are high up in our priority list.
Other Tools
swift-chat, a simple app demonstrating how to use this package.exporters, a Core ML conversion package for transformers models, based on Apple’scoremltools.transformers-to-coreml, a no-code Core ML conversion tool built onexporters.
Roadmap / To Do
- BPE family
- Fix Falcon, broken while porting BPE
- Improve tests, add edge cases, see https://github.com/xenova/transformers.js/blob/27920d84831e323275b38f0b5186644b7936e1a2/tests/generate_tests.py#L24
- Include fallback
tokenizer_config.json for known architectures whose models don’t have a configuration in the Hub (GPT2)
- Port other tokenizer types: Unigram, WordPiece
tokenizer_config.json for known architectures whose models don’t have a configuration in the Hub (GPT2)exporters – Core ML conversion tool.
- Allow max sequence length to be specified.
- Allow discrete shapes
- Return
logitsfrom converted Core ML model - Use
coremltools@mainfor latest fixes. In particular, this merged PR makes it easier to use recent versions of transformers.
- Nucleus sampling (we currently have greedy and top-k sampling)
- Use new
top-kimplementation inAccelerate. - Support discrete shapes in the underlying Core ML model by selecting the smallest sequence length larger than the input.
- Allow system prompt to be specified.
- How to define a system prompt template?
- Test a code model (to stretch system prompt definition)