TokenizeAndTag
Basic word tokenizer and tagger.
Used this project as means to understand Swift’s NaturalLanguage library.
Here are is some sample code to build a tokenizer. I had trouble taking the output from the tokenizer and placing it an array due to the output being of type SubString.
After researching on stack overflow I found out you can just wrap the SubString in a String wrapper and you are good to go.
func tokenizeText(text: String) {
let tokenizer = NLTokenizer(unit: .word)
tokenizer.string = text
tokenizer.setLanguage(.english)
tokenizer.enumerateTokens(in: text.startIndex..<text.endIndex) { (range, attributes) -> Bool in
let word = String(text[range])
tokenizedWords.append(word)
return true
}
}
Here are is some sample code to build a tagger. The tagger also tokenizes the words so in the end I ended up only using the tagger.
func tag(text: String) {
let tagger = NSLinguisticTagger(tagSchemes: [.lexicalClass], options: 0)
tagger.string = text
let range = NSRange(location: 0, length: text.utf16.count)
let options: NSLinguisticTagger.Options = [.omitPunctuation, .omitWhitespace]
tagger.enumerateTags(in: range, unit: .word, scheme: .lexicalClass, options: options) { tag, tokenRange, _ in
if let tag = tag {
let word = (text as NSString).substring(with: tokenRange)
tokenizedWords.append(word)
tags.append(tag.rawValue)
}
}
In terms of UI, it was really fun to add an expandable animated button.
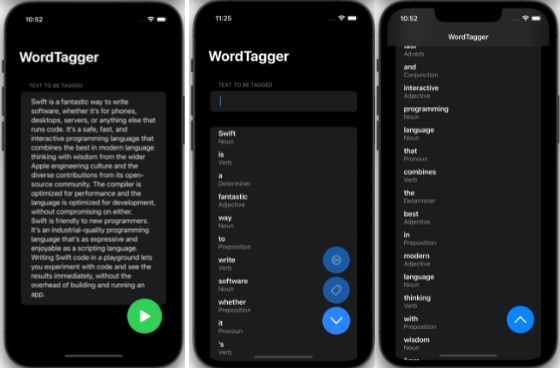
Screenshots
| Screenshots |
|---|
   |